



PaddleOCR TestWeb
PaddleOCR 的 Web 测试应用程序,提供 OCR 功能的 Web 界面。
下载地址:https://gitee.com/fightroad/test-ocrweb
功能特点
- 📷 图片OCR识别:支持 PNG、JPG、BMP 等图片格式
- 📄 PDF文档识别:支持PDF文档的OCR识别
- 🔧 文本后处理:提供多种文本后处理模式
- 🌐 Web界面:友好的Web操作界面
- ⚙️ 灵活配置:支持多种OCR参数配置
界面预览
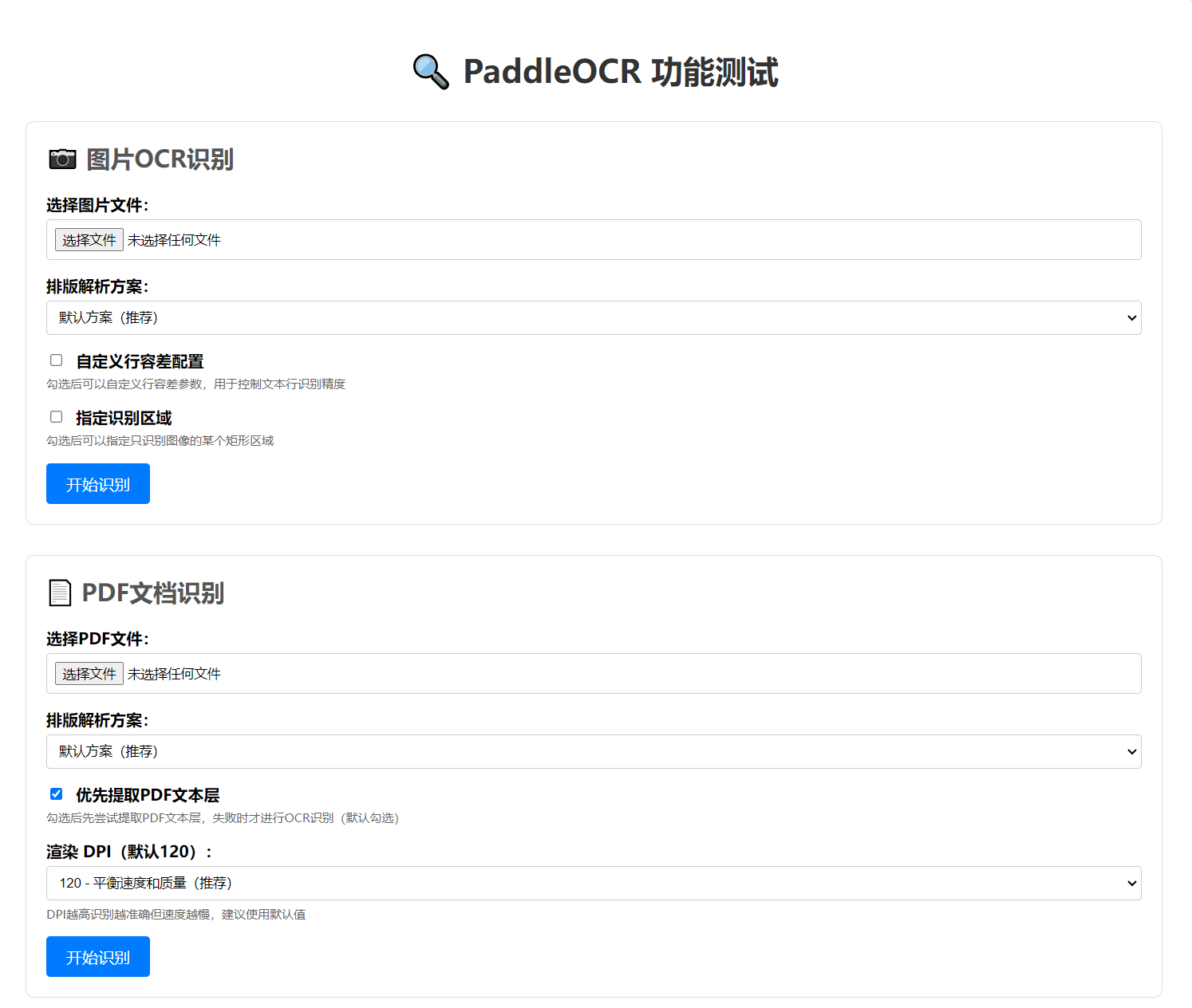
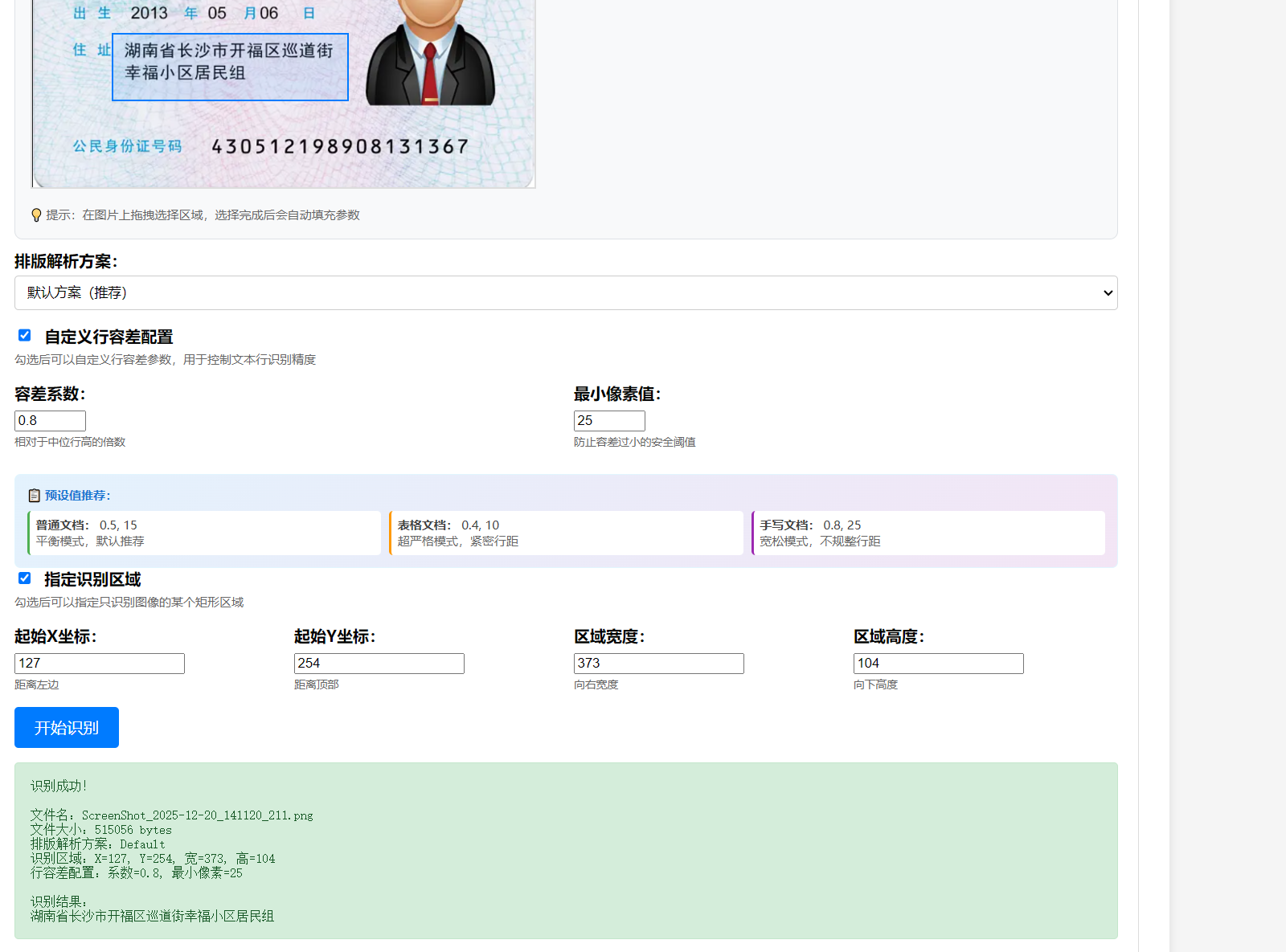
快速开始
# 运行程序
./TestWeb.exe
# 访问应用
# 浏览器打开:http://localhost:5000
使用说明
图片识别
- 选择图片文件
- 选择后处理模式
- 点击"开始识别"
- 查看识别结果
PDF识别
- 选择PDF文件
- 配置识别参数:
- 后处理模式
- 是否优先提取文本层
- 渲染DPI设置
- 点击"开始识别"
- 查看识别结果
文本后处理测试
- 输入测试文本(每行一个文本块)
- 选择后处理模式
- 点击"测试后处理"
- 查看处理结果
配置参数
PDF渲染DPI
| DPI值 | 说明 | 适用场景 |
|---|---|---|
| 96-100 | 速度最快 | 清晰的电子文档 |
| 120 | 平衡速度和质量(推荐) | 大部分PDF文档 |
| 150-200 | 高质量 | 复杂文档、小字体 |
| 300 | 打印质量 | 需要最高精度的场景 |
API 接口
图片识别
POST /api/ocr/recognize
Content-Type: multipart/form-data
参数:
- file: 图片文件
- mode: 后处理模式(可选)
PDF识别
POST /api/ocr/recognize-pdf
Content-Type: multipart/form-data
参数:
- file: PDF文件
- mode: 后处理模式(可选)
- tryExtractTextLayer: 是否优先提取文本层(可选)
- pdfRenderDpi: PDF渲染DPI(可选)
文本后处理测试
POST /api/ocr/test-post-process
Content-Type: application/json
参数:
- textBlocks: 文本块列表
- mode: 后处理模式
注意事项
- 首次使用:会自动下载OCR模型文件
- 文件大小:单exe文件较大(100-200MB),因为包含了.NET运行时
- 启动速度:首次启动可能较慢,后续启动会快一些
- 内存使用:OCR处理需要较多内存,建议至少4GB RAM
- 文件格式:支持常见图片格式和PDF文档
故障排除
常见问题
-
启动失败
- 检查端口5000是否被占用
-
OCR识别失败
- 检查图片文件是否损坏
- 检查文件格式是否支持
- 查看控制台错误信息
-
PDF识别失败
- 检查PDF文件是否损坏
- 检查PDF是否加密
- 尝试调整DPI设置
日志查看
程序运行时的日志会输出到控制台,可以查看详细的错误信息。
更新日志
v1.0.0
- 初始版本
- 支持图片和PDF的OCR识别
- 提供Web界面
- 支持多种文本后处理模式
- 支持单exe文件发布
评论区